模型训练
自定义模型训练逻辑
cogdl 支持选择自定义训练逻辑,“数据-模型-训练”三部分在 CogDL 中是独立的,研究者和使用者可以自定义其中任何一部分,并复用其他部分,从而提高开发效率。现在您可以使用 Cogdl 中的模型和数据集来实现您的个性化需求。
import torch
import torch.nn as nn
import torch.nn.functional as F
from cogdl import experiment
from cogdl.datasets import build_dataset_from_name
from cogdl.layers import GCNLayer
from cogdl.models import BaseModel
class Gnn(BaseModel):
def __init__(self, in_feats, hidden_size, out_feats, dropout):
super(Gnn, self).__init__()
self.conv1 = GCNLayer(in_feats, hidden_size)
self.conv2 = GCNLayer(hidden_size, out_feats)
self.dropout = nn.Dropout(dropout)
def forward(self, graph):
graph.sym_norm()
h = graph.x
h = F.relu(self.conv1(graph, self.dropout(h)))
h = self.conv2(graph, self.dropout(h))
return F.log_softmax(h, dim=1)
if __name__ == "__main__":
dataset = build_dataset_from_name("cora")[0]
model = Gnn(in_feats=dataset.num_features, hidden_size=64, out_feats=dataset.num_classes, dropout=0.1)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=5e-3)
model.train()
for epoch in range(300):
optimizer.zero_grad()
out = model(dataset)
loss = F.nll_loss(out[dataset.train_mask], dataset.y[dataset.train_mask])
loss.backward()
optimizer.step()
model.eval()
_, pred = model(dataset).max(dim=1)
correct = float(pred[dataset.test_mask].eq(dataset.y[dataset.test_mask]).sum().item())
acc = correct / dataset.test_mask.sum().item()
print('The accuracy rate obtained by running the experiment with the custom training logic: {:.6f}'.format(acc))
统一训练器
CogDL 为 GNN 模型提供了一个统一的训练器,它接管了训练过程的整个循环。包含大量工程代码的统一训练器可灵活实现以涵盖任意 GNN 训练设置
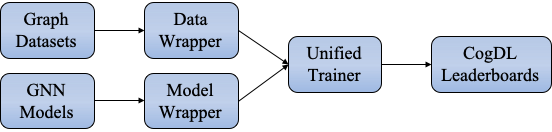
为了更方便的使用GNN 训练,我们设计了四个解耦模块,包括Model、Model Wrapper、Dataset、Data Wrapper。Model Wrapper用于训练和测试步骤,而Data Wrapper旨在构建Model Wrapper使用的数据加载器。 大多数 GNN 论文的主要贡献主要在于除Dataset之外的三个模块,如下表所示。例如,GCN 论文在(半)监督和全图设置下训练 GCN 模型,而 DGI 论文通过最大化局部-全局互信息来训练 GCN 模型。DGI 的训练方法被认为是一个dgi_mw的模型包装器,可以用于其他场景。
Paper |
Model |
Model Wrapper |
Data Wrapper |
|---|---|---|---|
GCN |
GCN |
supervised |
full-graph |
GAT |
GAT |
supervised |
full-graph |
GraphSAGE |
SAGE |
sage_mw |
neighbor sampling |
Cluster-GCN |
GCN |
supervised |
graph clustering |
DGI |
GCN |
dgi_mw |
full-graph |
基于统一训练器和解耦模块的设计,我们可以对模型、Model Wrapper和Data Wrapper进行任意组合。例如,如果我们想将 DGI 应用于大规模数据集,我们只需要用邻居采样或聚类数据包装器替换全图data wrapper,而无需额外修改。如果我们提出一个新的 GNN 模型,我们只需要为模型编写必要的 PyTorch 风格的代码。其余的可以通过指定Model Wrapper和Data Wrapper由 CogDL 自动处理。
我们可以通过 trainer = Trainer(epochs,...) 和 trainer.run(...). 此外,基于统一的训练器,CogDL 为许多有用的特性提供了原生支持,包括超参数优化、高效的训练技术和实验管理,而无需对模型实现进行任何修改。
Experiment API
CogDL在训练上提供了更易于使用的 API ,即Experiment 。我们以节点分类为例,展示如何使用 CogDL 完成使用 GNN 的工作流程。在监督设置中,节点分类旨在预测每个节点的真实标签。 CogDL 提供了丰富的通用基准数据集和 GNN 模型。一方面,您可以使用 CogDL 中的模型和数据集简单地开始运行。当您想要测试提出的 GNN 的可复现性或在不同数据集中获得基线结果时,使用Cogdl很方便。
from cogdl import experiment
experiment(model="gcn", dataset="cora")
或者,您可以单独创建每个组件并使用CogDL 中的 build_dataset , build_model 来手动运行该过程。
from cogdl import experiment
from cogdl.datasets import build_dataset
from cogdl.models import build_model
from cogdl.options import get_default_args
args = get_default_args(model="gcn", dataset="cora")
dataset = build_dataset(args)
model = build_model(args)
experiment(model=model, dataset=dataset)
如上所示,模型/数据集是建立训练过程的关键组成部分。事实上,CogDL 也支持自定义模型和数据集。这将在下一章介绍。下面我们将简要介绍每个组件的详细信息。
如何保存训练好的模型?
CogDL 支持使用 checkpoint_path 在命令行或 API 中保存训练的模型。例如:
experiment(model="gcn", dataset="cora", checkpoint_path="gcn_cora.pt")
当训练停止时,模型将保存在 gcn_cora.pt 中。如果你想从之前的checkpoint继续训练,使用不同的参数(如学习率、权重衰减等),保持相同的模型参数(如hidden size、模型层数),可以像下面这样做:
experiment(model="gcn", dataset="cora", checkpoint_path="gcn_cora.pt", resume_training=True)
在命令行中使用 --checkpoint-path {path} 和 --resume-training 可以获得相同的结果。
如何保存embeddings?
图表示学习(etwork embedding 和 无监督 GNNs)旨在获得节点表示。embeddings可用于各种下游应用。CogDL 会将节点embeddings保存在指定的路径通过 --save-emb-path {path}.
experiment(model="prone", dataset="blogcatalog", save_emb_path="./embeddings/prone_blog.npy")
对节点分类的评估将在训练结束时进行。我们在 DeepWalk、Node2Vec 和 ProNE 中使用的相同实验设置。我们随机抽取不同百分比的标记节点来训练一个
liblinear 分类器,并将剩余的用于测试,我们重复训练几次并输出平均 Micro-F1。默认情况下,CogDL 对 90% 的标记节点进行一次抽样训练。您可以根据自己的
需要使用 --num-shuffle 和 --training-percents 更改设置。
此外,CogDL 支持评估节点embeddings,而无需在不同的评估设置中进行训练。以下代码片段评估我们在上面得到的embeddings:
experiment(
model="prone",
dataset="blogcatalog",
load_emb_path="./embeddings/prone_blog.npy",
num_shuffle=5,
training_percents=[0.1, 0.5, 0.9]
)
您也可以使用命令行来实现相同的结果
# Get embedding
python script/train.py --model prone --dataset blogcatalog
# Evaluate only
python script/train.py --model prone --dataset blogcatalog --load-emb-path ./embeddings/prone_blog.npy --num-shuffle 5 --training-percents 0.1 0.5 0.9